Who Am I ?
About Me
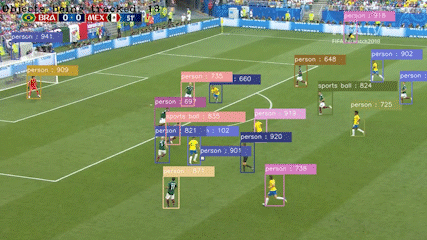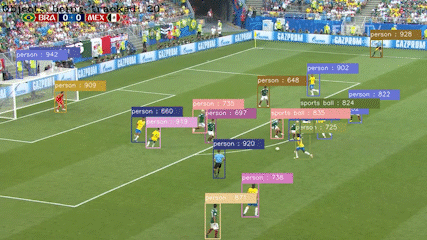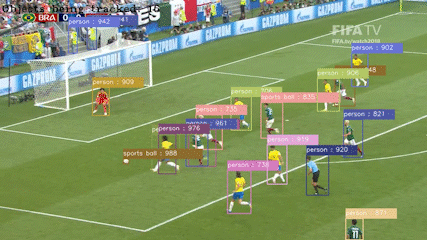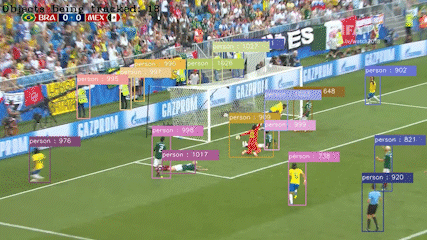
저는 대구가톨릭대학교 AI & 빅데이터 공학과에서 인공지능을 전공 하였습니다. 저는 객체 탐지 기술과 자율주행에 관심이 있습니다. 객체 탐지 기술을 통해 컴퓨터가 시각적인
정보를 처리하고, 직접 제공한 학습 데이터들을 기반으로 해당 개체가 무엇인지에 이해하는 과정에서 컴퓨터 비전이 매력적이라고 느껴졌습니다.
이후 어떻게 하면 현실의 시각적인 정보를 더 잘 알려줄 수 있을지 및 학습시킨 모델을 통해 어떤 창의적인 활동들을 생산해 낼 수 있을지 탐구하고 연구하는 과정에 흥미와
열의를 가질 수 있었습니다.
객체 탐지 기술을 통해 최종적으로 어떻게 자율주행이 완벽하게 이루어질 수 있는지에 대한 연구를 수행하고, 이를 바탕으로 차량이 주변 환경을 정확하게 탐지할 수 있는
능력을 갖춘 자율주행 시스템을 현실화한 미래에 도전해 보고 싶습니다.